 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
CoMotion: Concurrent Multi-person 3D Motion
Apr 16, 2025We introduce an approach for detecting and tracking detailed 3D poses of multiple people from a single monocular camera stream. Our system maintains temporally coherent predictions in crowded scenes filled with difficult poses and occlusions. Our model performs both strong per-frame detection and a learned pose update to track people from frame to frame. Rather than match detections across time, poses are updated directly from a new input image, which enables online tracking through occlusion. We train on numerous image and video datasets leveraging pseudo-labeled annotations to produce a model that matches state-of-the-art systems in 3D pose estimation accuracy while being faster and more accurate in tracking multiple people through time. Code and weights are provided at https://github.com/apple/ml-comotion
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Oct 02, 2024



We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions. We release code and weights at https://github.com/apple/ml-depth-pro
Unsupervised Contrastive Domain Adaptation for Semantic Segmentation
Apr 18, 2022
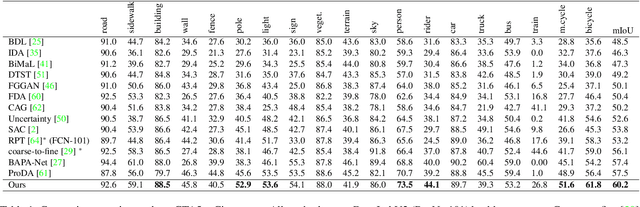
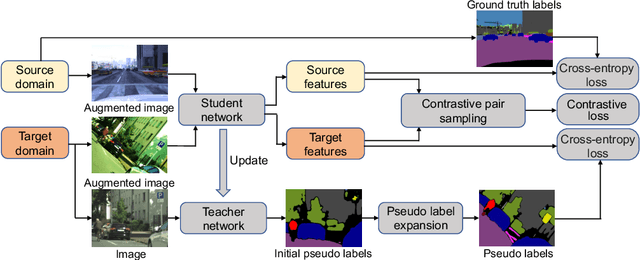
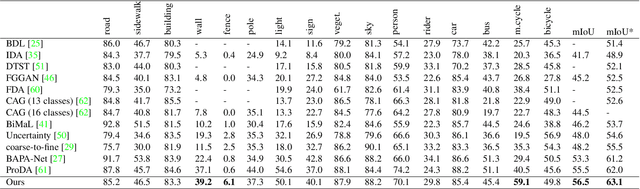
Semantic segmentation models struggle to generalize in the presence of domain shift. In this paper, we introduce contrastive learning for feature alignment in cross-domain adaptation. We assemble both in-domain contrastive pairs and cross-domain contrastive pairs to learn discriminative features that align across domains. Based on the resulting well-aligned feature representations we introduce a label expansion approach that is able to discover samples from hard classes during the adaptation process to further boost performance. The proposed approach consistently outperforms state-of-the-art methods for domain adaptation. It achieves 60.2% mIoU on the Cityscapes dataset when training on the synthetic GTA5 dataset together with unlabeled Cityscapes images.
Dancing under the stars: video denoising in starlight
Apr 08, 2022
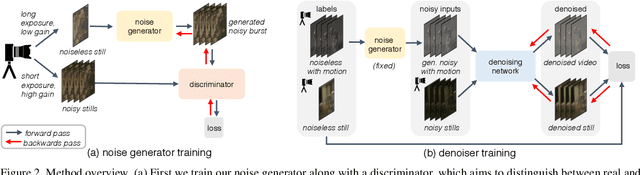
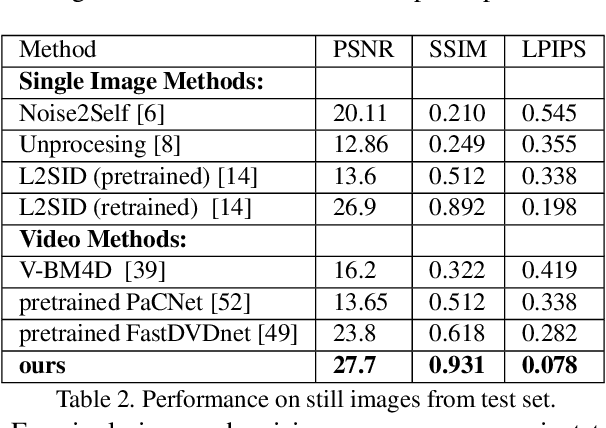
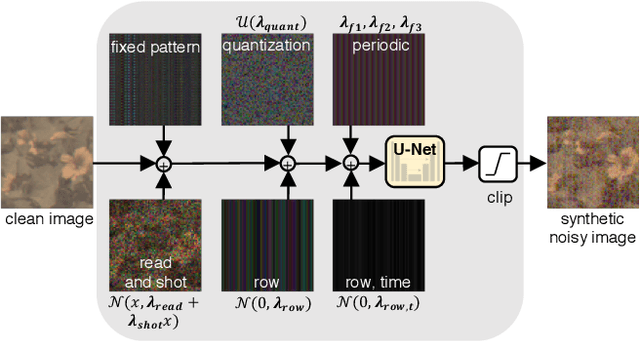
Imaging in low light is extremely challenging due to low photon counts. Using sensitive CMOS cameras, it is currently possible to take videos at night under moonlight (0.05-0.3 lux illumination). In this paper, we demonstrate photorealistic video under starlight (no moon present, $<$0.001 lux) for the first time. To enable this, we develop a GAN-tuned physics-based noise model to more accurately represent camera noise at the lowest light levels. Using this noise model, we train a video denoiser using a combination of simulated noisy video clips and real noisy still images. We capture a 5-10 fps video dataset with significant motion at approximately 0.6-0.7 millilux with no active illumination. Comparing against alternative methods, we achieve improved video quality at the lowest light levels, demonstrating photorealistic video denoising in starlight for the first time.
Enhancing Photorealism Enhancement
May 10, 2021
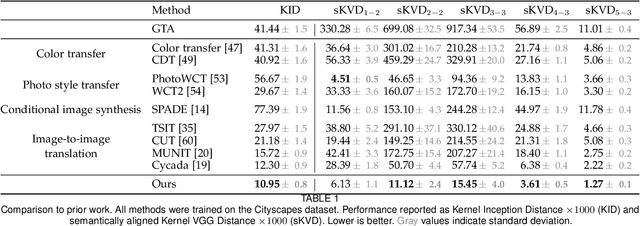

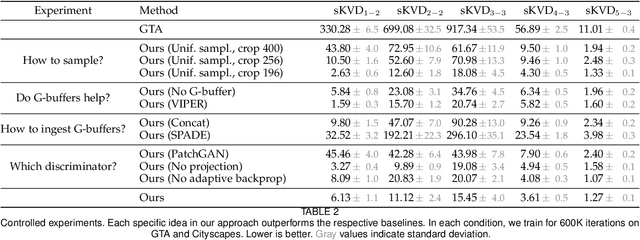
We present an approach to enhancing the realism of synthetic images. The images are enhanced by a convolutional network that leverages intermediate representations produced by conventional rendering pipelines. The network is trained via a novel adversarial objective, which provides strong supervision at multiple perceptual levels. We analyze scene layout distributions in commonly used datasets and find that they differ in important ways. We hypothesize that this is one of the causes of strong artifacts that can be observed in the results of many prior methods. To address this we propose a new strategy for sampling image patches during training. We also introduce multiple architectural improvements in the deep network modules used for photorealism enhancement. We confirm the benefits of our contributions in controlled experiments and report substantial gains in stability and realism in comparison to recent image-to-image translation methods and a variety of other baselines.
MeshSDF: Differentiable Iso-Surface Extraction
Jun 06, 2020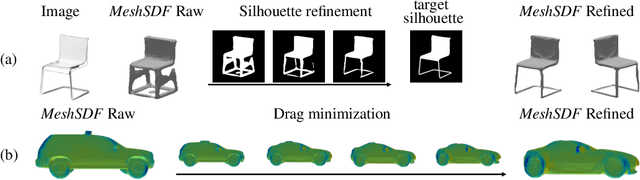
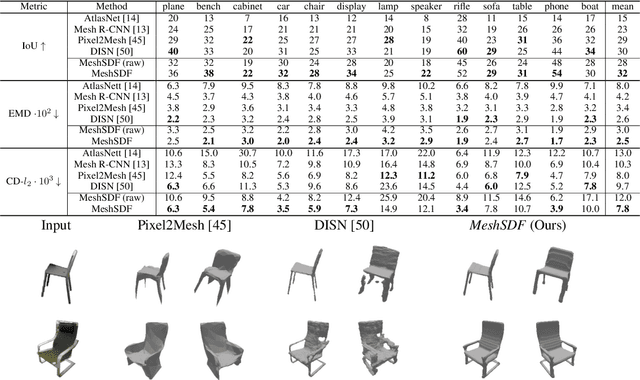
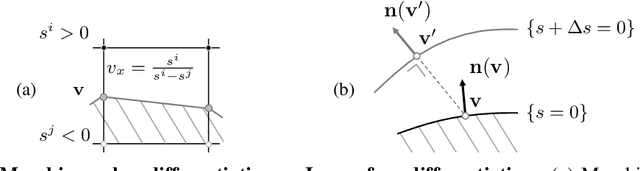
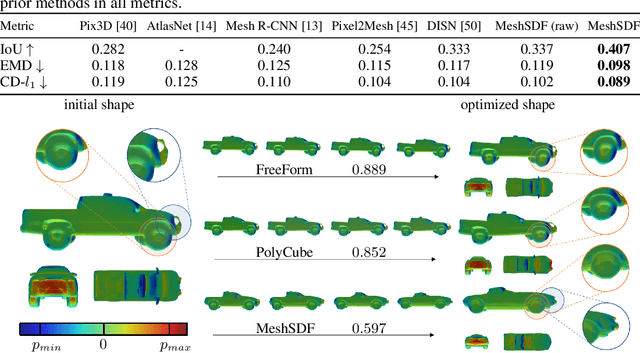
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is not limited in resolution. Unfortunately, these methods are often not suitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Signed Distance Functions. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define MeshSDF, an end-to-end differentiable mesh representation which can vary its topology. We use two different applications to validate our theoretical insight: Single-View Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our differentiable parameterization gives us an edge over state-of-the-art algorithms.
What Do Single-view 3D Reconstruction Networks Learn?
May 09, 2019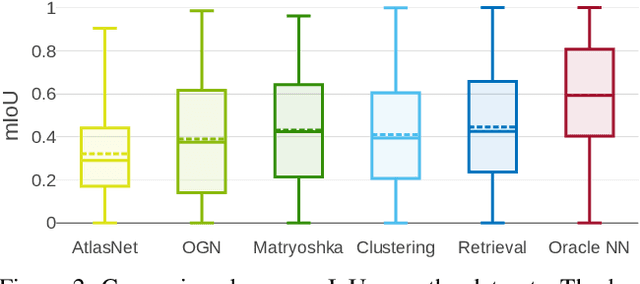
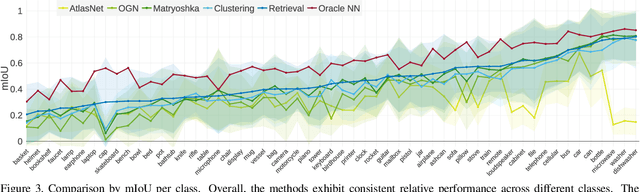
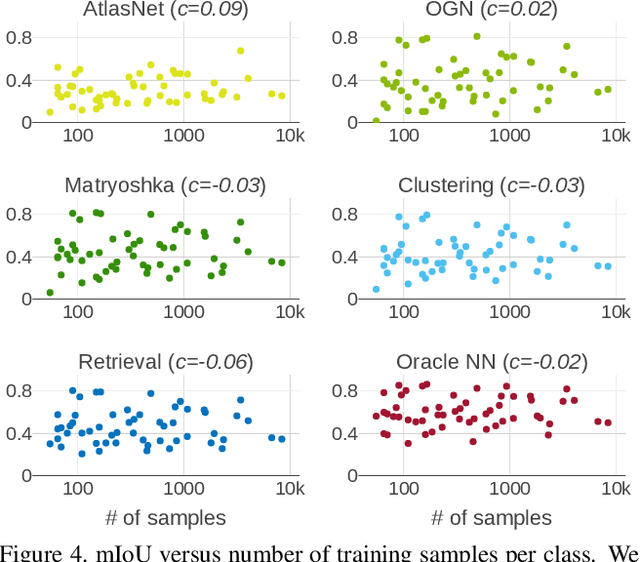

Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers
Apr 29, 2018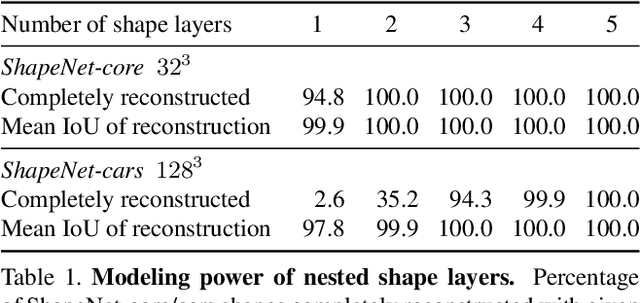
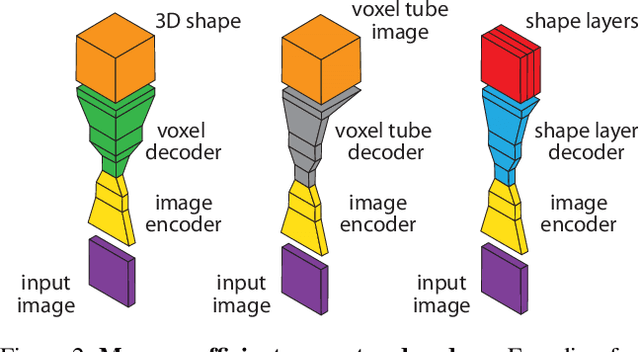
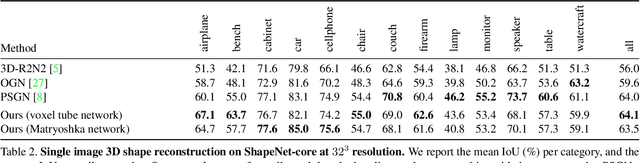

In this paper, we develop novel, efficient 2D encodings for 3D geometry, which enable reconstructing full 3D shapes from a single image at high resolution. The key idea is to pose 3D shape reconstruction as a 2D prediction problem. To that end, we first develop a simple baseline network that predicts entire voxel tubes at each pixel of a reference view. By leveraging well-proven architectures for 2D pixel-prediction tasks, we attain state-of-the-art results, clearly outperforming purely voxel-based approaches. We scale this baseline to higher resolutions by proposing a memory-efficient shape encoding, which recursively decomposes a 3D shape into nested shape layers, similar to the pieces of a Matryoshka doll. This allows reconstructing highly detailed shapes with complex topology, as demonstrated in extensive experiments; we clearly outperform previous octree-based approaches despite having a much simpler architecture using standard network components. Our Matryoshka networks further enable reconstructing shapes from IDs or shape similarity, as well as shape sampling.
Playing for Benchmarks
Sep 21, 2017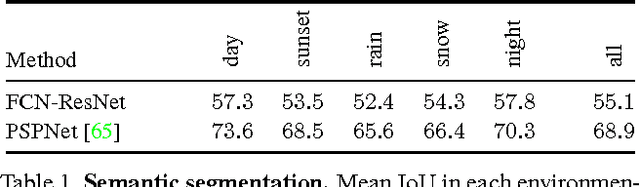
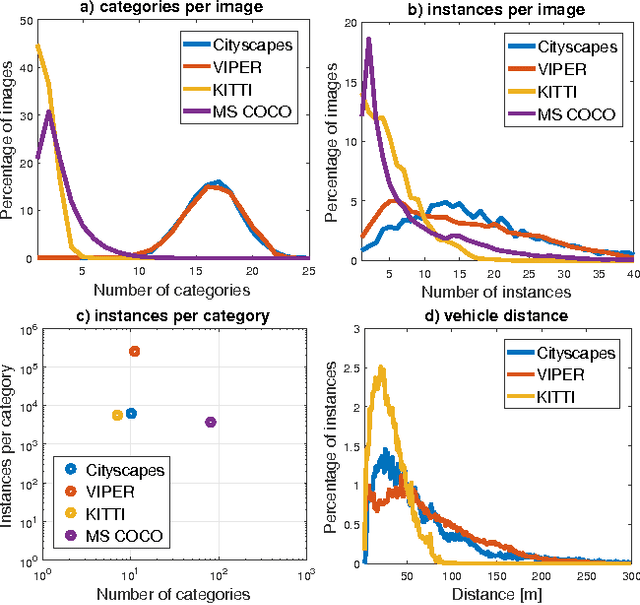
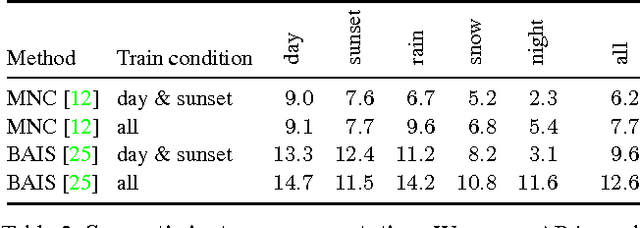
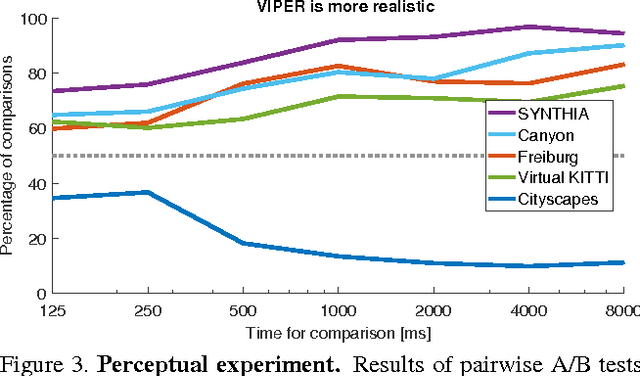
We present a benchmark suite for visual perception. The benchmark is based on more than 250K high-resolution video frames, all annotated with ground-truth data for both low-level and high-level vision tasks, including optical flow, semantic instance segmentation, object detection and tracking, object-level 3D scene layout, and visual odometry. Ground-truth data for all tasks is available for every frame. The data was collected while driving, riding, and walking a total of 184 kilometers in diverse ambient conditions in a realistic virtual world. To create the benchmark, we have developed a new approach to collecting ground-truth data from simulated worlds without access to their source code or content. We conduct statistical analyses that show that the composition of the scenes in the benchmark closely matches the composition of corresponding physical environments. The realism of the collected data is further validated via perceptual experiments. We analyze the performance of state-of-the-art methods for multiple tasks, providing reference baselines and highlighting challenges for future research. The supplementary video can be viewed at https://youtu.be/T9OybWv923Y